Ruby 3のパターンマッチング応用(1)ポーカーゲーム(翻訳)
Ruby 3.0の目玉機能としてパターンマッチング(pattern matching)が導入されました。しかしパターンマッチングをどう使いこなせばよいのか、またパターンマッチングがどんなときに欲しくなるか、といった全貌がまだ見えていない方も大勢いらっしゃることでしょう。
本記事では、ポーカーゲームでハンド(hand: 役)のスコアをパターンマッチングで算出する方法をご紹介します。
![Arsene Lemur on a playing card]()
![🔗]() 最終的なプログラム
最終的なプログラム
最初に最終的なスクリプト全体をお目にかけます。その後で、個別のパートについて少しずつ見ていくことにします。
読み進めるうちに少々戸惑う部分もあるかと思いますが、何が行われているのかを頑張って読み取ってみましょう。
Card = Struct.new(:suit, :rank) do
include Comparable
def precedence() = [SUITS_SCORES[self.suit], RANKS_SCORES[self.rank]]
def rank_precedence() = RANKS_SCORES[self.rank]
def suit_precedence() = SUITS_SCORES[self.rank]
def <=>(other) = self.precedence <=> other.precedence
def to_s() = "#{self.suit}#{self.rank}"
end
Hand = Struct.new(:cards) do
def sort() = Hand[self.cards.sort]
def sort_by_rank() = Hand[self.cards.sort_by(&:rank_precedence)]
def to_s() = self.cards.map(&:to_s).join(', ')
end
SUITS = %w(S H D C).freeze
SUITS_SCORES = SUITS.each_with_index.to_h
RANKS = [*2..10, *%w(J Q K A)].map(&:to_s).freeze
RANKS_SCORES = RANKS.each_with_index.to_h
SCORES = %i(
royal_flush
straight_flush
four_of_a_kind
full_house
flush
straight
three_of_a_kind
two_pair
one_pair
high_card
).reverse_each.with_index(1).to_h.freeze
CARDS = SUITS.flat_map { |s| RANKS.map { |r| Card[s, r] } }.freeze
def hand_score(unsorted_hand)
hand = Hand[unsorted_hand].sort_by_rank.cards
is_straight = -> hand {
hand
.map { RANKS_SCORES[_1.rank] }
.sort
.each_cons(2)
.all? { |a, b| b - a == 1 }
}
return SCORES[:royal_flush] if hand in [
Card[s, '10'], Card[^s, 'J'], Card[^s, 'Q'], Card[^s, 'K'], Card[^s, 'A']
]
return SCORES[:straight_flush] if is_straight[hand] && hand in [
Card[s, *], Card[^s, *], Card[^s, *], Card[^s, *], Card[^s, *]
]
return SCORES[:four_of_a_kind] if hand in [
*, Card[*, r], Card[*, ^r], Card[*, ^r], Card[*, ^r], *
]
return SCORES[:full_house] if hand in [
Card[*, r1], Card[*, ^r1], Card[*, ^r1], Card[*, r2], Card[*, ^r2]
]
return SCORES[:full_house] if hand in [
Card[*, r1], Card[*, ^r1], Card[*, r2], Card[*, ^r2], Card[*, ^r2]
]
return SCORES[:flush] if hand in [
Card[s, *], Card[^s, *], Card[^s, *], Card[^s, *], Card[^s, *]
]
return SCORES[:straight] if is_straight[hand]
return SCORES[:three_of_a_kind] if hand in [
*, Card[*, r], Card[*, ^r], Card[*, ^r], *
]
return SCORES[:two_pair] if hand in [
*, Card[*, r1], Card[*, ^r1], Card[*, r2], Card[*, ^r2], *
]
return SCORES[:two_pair] if hand in [
Card[*, r1], Card[*, ^r1], *, Card[*, r2], Card[*, ^r2]
]
return SCORES[:one_pair] if hand in [
*, Card[*, r], Card[*, ^r], *
]
SCORES[:high_card]
end
# --- テスト ------
EXAMPLES = {
royal_flush:
RANKS.last(5).map { Card['S', _1] },
straight_flush:
RANKS.first(5).map { Card['S', _1] },
four_of_a_kind:
[CARDS[0], *SUITS.map { Card[_1, 'A'] }],
full_house:
SUITS.first(3).map { Card[_1, 'A'] } +
SUITS.first(2).map { Card[_1, 'K'] },
flush:
(0..RANKS.size).step(2).first(5).map { Card['S', RANKS[_1]] },
straight:
[Card['H', RANKS.first], *RANKS[1..4].map { Card['S', _1] }],
three_of_a_kind:
CARDS.first(2) +
SUITS.first(3).map { Card[_1, 'A'] },
two_pair:
CARDS.first(1) +
SUITS.first(2).flat_map { [Card[_1, 'A'], Card[_1, 'K']] },
one_pair:
[CARDS[10], CARDS[15], CARDS[20], *SUITS.first(2).map { Card[_1, 'A'] }],
high_card:
[CARDS[10], CARDS[15], CARDS[20], CARDS[5], Card['S', 'A']]
}.freeze
SCORE_MAP = SCORES.invert
EXAMPLES.each do |hand_type, hand|
score = hand_score(hand)
correct_text = hand_type == SCORE_MAP[score] ? 'correct' : 'incorrect'
puts <<~OUT
Hand: #{Hand[hand]} (#{hand_type})
Score: #{score} (#{correct_text})
OUT
puts
end
上のスクリプトにはさまざまなものが盛り込まれています。ここだけ読んで理解に不安があってもご心配なく。本記事でこの後詳しく解説いたします。
それでは深堀りを始めます。よろしいですか?
![🔗]() 変動しない部分
変動しない部分
まずはスクリプトの定数部から見ていきましょう。
SUITS = %w(S H D C).freeze
SUITS_SCORES = SUITS.each_with_index.to_h
RANKS = [*2..10, *%w(J Q K A)].map(&:to_s).freeze
RANKS_SCORES = RANKS.each_with_index.to_h
SCORES = %i(
royal_flush
straight_flush
four_of_a_kind
full_house
flush
straight
three_of_a_kind
two_pair
one_pair
high_card
).reverse_each.with_index(1).to_h.freeze
CARDS = SUITS.flat_map { |s| RANKS.map { |r| Card[s, r] } }.freeze
![🔗]() スート
スート
定数部の冒頭はスート(suit: カードの種類)です。ショートハンドとして「スペード」「ハート」「ダイヤ」「クラブ」という4つのスートの頭文字だけを取り出して定義しています。
SUITS = %w(S H D C).freeze
SUITS_SCORES = SUITS.each_with_index.to_h
スートもスコアリングに使いたいので、each_with_index.to_hを用いてスートの強さの順に手早くインデックス化しておきます。こうしておけば、スートの配列全体をコードのあちこちで生書きせずに済みます。
![🔗]() ランク
ランク
定数部の次はランク(rank: 2〜10、J、Q、K、Aまでのカードの順位)です。2からA(エース)までのランクを、「数値」または「絵札やエースの頭文字」で表現します。
RANKS = [*2..10, *%w(J Q K A)].map(&:to_s).freeze
RANKS_SCORES = RANKS.each_with_index.to_h
上のmap(&:to_s)は、ランクの要素の型を一貫させています。それを次のeach_with_index.to_hでランクと強さ(優先順位)を対応付けています。ランクがすべて数値なら話は早いのですが、ランクには絵札も含まれている点が少しだけ面倒なので、このように書きました。
![🔗]() スコア
スコア
お次は、ハンドのランキングを一番強いロイヤルフラッシュから最も弱いハイカードまで定義します。
SCORES = %i(
royal_flush
straight_flush
four_of_a_kind
full_house
flush
straight
three_of_a_kind
two_pair
one_pair
high_card
).reverse_each.with_index(1).to_h.freeze
コードを読むときは上から強い順に並べて読みたいですよね。上のコードでは読みやすさを優先して、reverse_eachで逆順にし、ロイヤルフラッシュが最高得点になるようにしています。これはあくまで読みやすさのための最適化です(余談ですが、この後パターンマッチングが本領発揮しますのであらかじめ予告しておきます)。
with_index(1)はインデックスを0ではなく1から始まるように変えます。そしてto_hはハンドの種類とスコアを対応付けてくれます。欲しかったのはこれです。
![🔗]() カード
カード
最後に、カードを一組作る必要があります。
CARDS = SUITS.flat_map { |s| RANKS.map { |r| Card[s, r] } }.freeze
このCard(およびクラスのブラケット記法[])はこの後すぐ使います。今私たちがやっているのは、カードのすべてのRANKSを適用した4つのスートをすべて持つSUITSを作ることです。言い換えれば、ジョーカーを除く52枚のカード一組を作ることです。
![🔗]()
Structを追加する
RubyのStructは、完全なクラスが欲しいわけではない場合にとても重宝します。私の場合は、initializeを入力したくない10行程度のコードでStructを使う傾向があります。
Card = Struct.new(:suit, :rank) do
include Comparable
def precedence() = [SUITS_SCORES[self.suit], RANKS_SCORES[self.rank]]
def rank_precedence() = RANKS_SCORES[self.rank]
def suit_precedence() = SUITS_SCORES[self.rank]
def <=>(other) = self.precedence <=> other.precedence
def to_s() = "#{self.suit}#{self.rank}"
end
Hand = Struct.new(:cards) do
def sort() = Hand[self.cards.sort]
def sort_by_rank() = Hand[self.cards.sort_by(&:rank_precedence)]
def to_s() = self.cards.map(&:to_s).join(', ')
end
![🔗]()
Structを作成する
Structはどのように振る舞うのでしょうか?Structは以下のように属性のリストを受け取り、シンプルなデータコンテナとして振る舞います。
Card = Struct.new(:suit, :rank)
雑に申し上げれば、上のコードは以下のクラス定義と同等です。
class Card
attr_accessor :suit, :rank
def initialize(suit, rank)
@suit = suit
@rank = rank
end
end
でもStructなら同じことをたった1行でやれます。これで私はコードのデモに集中できるというわけです。
![🔗]()
Structはブロックを受け取れる
Structコンストラクタは、Struct内でのメソッド定義のためにブロックを受け取れます。なお、そこまでやるようになったら、それは「クラスを作る方がいいかもよ」の合図の可能性があります。しかし今はStructのままの方が解説を楽しく続けられますし、必要以上にコードを増やしたくありません。
Card = Struct.new do
def method_on_card
'foo!'
end
end
Card.new.method_on_card
# => 'foo!'
# Just an alias for new:
Card[].method_on_card
# => 'foo!'
![🔗]()
Comparableを導入する
カード同士を比較できるようにしたいのと、カードと数値の対応付けが明確でないため、カードのソートにはRubyの助けを少々借りることにします。
Card = Struct.new(:suit, :rank) do
include Comparable
def precedence() = [SUITS_SCORES[self.suit], RANKS_SCORES[self.rank]]
def rank_precedence() = RANKS_SCORES[self.rank]
def suit_precedence() = SUITS_SCORES[self.rank]
def <=>(other) = self.precedence <=> other.precedence
def to_s() = "#{self.suit}#{self.rank}"
end
Comparableを用いれば、<=>(宇宙船演算子もしくは比較器)を実装するだけで、Enumerableとeachと似た感じであらゆるソートをクラスで使えるようになります。今回使う<=>は以下のようになっています。
def <=>(other) = self.precedence <=> other.precedence
上ではRuby 3の1行メソッド(endレスメソッド定義)を使って、あるカードが他のカードよりも強いかどうかを比較しています。ここでは並び順を強さの順として使っています。
def precedence() = [SUITS_SCORES[self.suit], RANKS_SCORES[self.rank]]
ここでArrayが登場する理由は何でしょうか?デフォルトではまずスートでソートし、それからランクでソートしたいからです。スペードはハートより強く、エースは他のランクよりも強いといった具合です。
パターンマッチングでは順序が一貫していることを前提とするので、以下では主にrank_precedenceが頼りとなります。このスクリプトでは通常の並び順は通用しないので、単なるデモ用です。
![🔗]()
to_s
文字列で表現しておくとデバッグでとても有用です。ここではCardをスートとランクで表現しています。以下は何のひねりもない普通のコードです。
def to_s() = "#{self.suit}#{self.rank}"
![🔗]() ハンド
ハンド
今度は、今やっていることを正確に把握するために「ハンド」の概念が欲しくなってきました。
Hand = Struct.new(:cards) do
def sort() = Hand[self.cards.sort]
def sort_by_rank() = Hand[self.cards.sort_by(&:rank_precedence)]
def to_s() = self.cards.map(&:to_s).join(', ')
end
上のコードでは、sortのようなメソッドでオブジェクトを改変するのではなく、新しいオブジェクトを返そうとしていることにお気づきの方もいらっしゃるかもしれません。このスタイルはほぼ関数型言語に近く、テストデータを何度も改変せずに済みます。
クラスやstructは、複雑なものでなければならないという決まりはありません。これらは単にいくつかの値を提供して配列のソートを繰り返し、文字列をいつでも出力できるというだけです。
![🔗]() ハンドのスコアを算出する
ハンドのスコアを算出する
いよいよこのプログラムの本当に美味しい部分にたどり着きました。ここではかなりいろんなことをやっています。
![🔗]() ハンドをソートする
ハンドをソートする
ハンドのスコアを出すには、パターンマッチングが効くように順序を揃える必要があります。
hand = Hand[unsorted_hand].sort_by_rank.cards
このHandにはおそらくArrayで使われそうなメソッドを追加するので(といってもここではソートしたいだけですが)、Enumerableにしておいてそこにパターンマッチングのフックを追加します。
![🔗]() ストレートの判定とソート
ストレートの判定とソート
パターンマッチングでは、ありうるパターンをすべて網羅しておかないと、ストレートを含む手をうまくチェックできません。自分がせっかくハンマーを持っていても、周りにあるのが全部釘だとは限りません。今回はまさにそうしたケースです。そこで、ここではlambda関数をひとつこしらえて、ストレート的なハンドで以下のように数回ほど再利用できるようにします。
is_straight = -> hand {
hand
.map { RANKS_SCORES[_1.rank] }
.sort
.each_cons(2)
.all? { |a, b| b - a == 1 }
}
ここでは、カードごとのスコアがどのランクに相当するかを表すために、自分のハンドをmapしたいと思います。ここではスートのことは考えません。続いてハンドをソートし、each_cons(2)で2枚のカードのそれぞれの後続グループを取得したいと思います。
ここでのポイントは、どのペアもカード同士のランクが1つしか離れていないようにしたい、つまりストレートの一部であることを確認したいということです。
![🔗]() ロイヤルフラッシュ
ロイヤルフラッシュ
いよいよ本記事で最も興味津々の部分に差し掛かってきました。まずは以下のようにパターンマッチングを1行に収めてみました。
return SCORES[:royal_flush] if hand in [
Card[s, '10'], Card[^s, 'J'], Card[^s, 'Q'], Card[^s, 'K'], Card[^s, 'A']
]
ロイヤルフラッシュ(royal flush)は、同一スートのカードが10からAまで連続することを指します。このパターンマッチングでは、sで最初のスートをキャプチャし、その後ろに^s(ピン演算子^とs)を記述することで、すべてのカードのスートが同一であるという期待を示します。
たとえば最初のカードのスートがスペードなら、残りのカードのスートもスペードであることを期待します。そうでない場合は次のパターンに進みます。
ところで、Card[...]という記述にお気づきでしょうか。この構文はパターンマッチで属性にアクセスするためのもので、Structに限らずあらゆるクラスで利用できます。この動作の細かなニュアンスについてもっと詳しく説明するには私がもっと実験を重ねる必要がありますが、とりあえず今はStructできれいに動いています。
私は「左から右に進む」スタイルが好みなので、return score if matchという種類の構文にしています。複数行によるパターンマッチを使う手も一応考えられますが、ストレートのチェックがうまくいかなくなって厄介なことになりそうです。
![🔗]() ストレートフラッシュ
ストレートフラッシュ
お次もなかなか興味深い内容です。もしここでパターンマッチングを使いすぎると、コードが短くならずに逆に増えて見づらくなる可能性もあります。そこで、ここでは先ほどのストレートチェックを元にしています。
return SCORES[:straight_flush] if is_straight[hand] && hand in [
Card[s, *], Card[^s, *], Card[^s, *], Card[^s, *], Card[^s, *]
]
ハンドがストレートで、しかもカードのスートがすべて揃っていれば勝ちです。sと^sを使っている点は先ほどと同様です。初登場の*は、値はここでは重要ではないのでそのままにすることを表します。
![🔗]() フォーカード
フォーカード
フォーカード(原文ではFour of a Kind)は、カードのランクは同じでスートがどれも異なるというハンドです。
return SCORES[:four_of_a_kind] if hand in [
*, Card[*, r], Card[*, ^r], Card[*, ^r], Card[*, ^r], *
]
rは上述のsと同じアイデアです。そして残りの部分はピン演算子でランクをピン留めすることで、4枚のカードのランクが同じであることを記述します。ここではスートは重要ではありません。一組のカードの中にある同じランクのカードは4枚ずつありますが、4枚のどれもスートが異なることはわかりきっているので、同じランクのカードを4枚キャプチャすれば自動的にスートは異なるものになります。
今度は*の置き場所が少し変わっていることにお気づきでしょうか。ここでは*を2箇所で探索に使っています。フォーカードは自分のハンドのうち、4枚のカードで成立すればよいので、ハンドの冒頭や末尾は任意のカードでよいことを*で表しています。つまり、たとえばAAAAKやKAAAAというパターンはいずれもフォーカードとして有効です。
![🔗]() フルハウス
フルハウス
これも興味深い内容です。しかもコードが少々これまでと趣が異なっています。
return SCORES[:full_house] if hand in [
Card[*, r1], Card[*, ^r1], Card[*, ^r1], Card[*, r2], Card[*, ^r2]
]
return SCORES[:full_house] if hand in [
Card[*, r1], Card[*, ^r1], Card[*, r2], Card[*, ^r2], Card[*, ^r2]
]
パターンが2つある理由がおわかりでしょうか?最初の理由は「|(論理ORを表します)を使う場合は、名前付きキャプチャやピン演算子が使えない」からです。ここでは無理せずマッチを2つに分けなければなりません。
フルハウスは、言ってみれば「スリーカード(Three of a Kind)」と「ワンペア(原文ではTwo of a Kind)」の合わせ技で、AAABBやAABBBのように2つの異なるパターンでできています。1つ目のコードでは、冒頭の3枚のカードをr1で、末尾の2枚のカードをr2で表しています。そして2つ目のコードではそれらを入れ替えてチェックしています。
![🔗]() フラッシュ
フラッシュ
フラッシュでは、自分のハンドのスートがすべて揃っていることを確認します。
return SCORES[:flush] if hand in [
Card[s, *], Card[^s, *], Card[^s, *], Card[^s, *], Card[^s, *]
]
sを使っている点はこれまでと同様です。残りのカードのスートがすべて冒頭のカードのスートと同じであることを^sで表しています。
![🔗]() ストレート
ストレート
ストレートでは、カードのランクが飛び番にならずにひと続きになっていることを確認します。カードのスートは揃っていなくてもよい点がストレートフラッシュと違います。このときのために、先ほどlambda関数を仕込んでおいたのです。
return SCORES[:straight] if is_straight[hand]
![🔗]() スリーカード
スリーカード
スリーカード(原文ではThree of a Kind)は上述のフォーカードとよく似ていますが、同じランクのカードが4枚ではなく3枚あればよい点が異なります。
return SCORES[:three_of_a_kind] if hand in [
*, Card[*, r], Card[*, ^r], Card[*, ^r], *
]
3枚のカードのうち、冒頭のカードのランクをrでキャプチャして残りの2枚のカードをピン留めします。冒頭と末尾の*は、真ん中で定義されている3枚のカードが隣り合っている限り、残りの2枚のカードは何でもよいことを表します。たとえばKAAAQやKQAAAやAAAKQは、いずれもエースが3枚連続で並んでいるのですべて有効です。
![🔗]() ツーペア
ツーペア
ツーペアはフルハウスと似ていますが、スリーカードがない点が異なります。
return SCORES[:two_pair] if hand in [
*, Card[*, r1], Card[*, ^r1], Card[*, r2], Card[*, ^r2], *
]
return SCORES[:two_pair] if hand in [
Card[*, r1], Card[*, ^r1], *, Card[*, r2], Card[*, ^r2]
]
ここでは、異なるペアが2つあることを確認するために、r1と^r1、r2と^r2をそれぞれ用いています。その次のコードは、言ってみればセカンドマッチというトリックです。異なるペアが2つある場合、2つのペアの間に別なカードが挟まる可能性があるので、それをキャプチャするのに使います。
カードはソート済みという前提で進めているので、ここまで何の問題も生じていません。でもここでひとつお楽しみの機能をご紹介しますので、必要になりましたらお使いください。
![🔗]() ワンペア
ワンペア
チェックがあとひとつ残っていましたね。
return SCORES[:one_pair] if hand in [
*, Card[*, r], Card[*, ^r], *
]
上のコードでやっていることはこれまでと同様ですが、同じランクのカードが2枚、つまりペアがひとつありさえすればワンペアになります。スートをチェックする必要がない点もこれまでどおりです。
![🔗]() ハイカード
ハイカード
いよいよ最後のハンドです。他のどれにもマッチしない場合はハイカード(High Card: 日本ではノーペアとも呼ばれるようです)を返し、カードをソートすることでハイカード同士のどちらが最終的に点が高いかを示します。
SCORES[:high_card]
これでスコアが取れました!
![🔗]() テストと実行例
テストと実行例
後はテストコードをいくらか追加して、すべてうまく動いていることを確認するだけです。
EXAMPLES = {
royal_flush:
RANKS.last(5).map { Card['S', _1] },
straight_flush:
RANKS.first(5).map { Card['S', _1] },
four_of_a_kind:
[CARDS[0], *SUITS.map { Card[_1, 'A'] }],
full_house:
SUITS.first(3).map { Card[_1, 'A'] } +
SUITS.first(2).map { Card[_1, 'K'] },
flush:
(0..RANKS.size).step(2).first(5).map { Card['S', RANKS[_1]] },
straight:
[Card['H', RANKS.first], *RANKS[1..4].map { Card['S', _1] }],
three_of_a_kind:
CARDS.first(2) +
SUITS.first(3).map { Card[_1, 'A'] },
two_pair:
CARDS.first(1) +
SUITS.first(2).flat_map { [Card[_1, 'A'], Card[_1, 'K']] },
one_pair:
[CARDS[10], CARDS[15], CARDS[20], *SUITS.first(2).map { Card[_1, 'A'] }],
high_card:
[CARDS[10], CARDS[15], CARDS[20], CARDS[5], Card['S', 'A']]
}.freeze
SCORE_MAP = SCORES.invert
EXAMPLES.each do |hand_type, hand|
score = hand_score(hand)
correct_text = hand_type == SCORE_MAP[score] ? 'correct' : 'incorrect'
puts <<~OUT
Hand: #{Hand[hand]} (#{hand_type})
Score: #{score} (#{correct_text})
OUT
puts
end
条件にマッチするハンドをいくつかテストコードに盛り込んであります。いくつかについては、ハンドの残りの部分を有効な範囲で任意のカードで埋めています。カードを埋めるときは、誤って他のハンドができないように注意しつつ自分の好きな数字を入れています。
これまで触れていなかった部分について駆け足で説明します。
![🔗]() 番号指定パラメータ
番号指定パラメータ
Ruby 3では以下のような「番号指定パラメータ(numbered parameter)」という機能が導入されました。
RANKS.last(5).map { Card['S', _1] }
上は「最もランクの大きい5枚のカード」「スートはすべてスペード」を表します。この_1は、関数の第1パラメータを暗に示しています。
![🔗]() splat演算子
splat演算子
Rubyのsplat演算子*は、配列の要素をばらして関数や別のコレクションに渡すのに使えます。splat演算子で得られるのは、ネストしていない1個のフラットな配列です。私はsplat演算子を使うこともあれば配列の結合を使うこともありますが、本記事のコードでは以下の例のように一貫しているわけではありません。
[CARDS[0], *SUITS.map { Card[_1, 'A'] }]
![🔗]()
first
Rubyのfirstは配列の最初の要素を返します。first(n)とすると、配列の冒頭からn番目の要素を返します。1を指定したときに配列の最初の要素を返してはいけないという決まりはありません。本記事のコードではsplat演算子の代わりに使える前提としていますが、既に申し上げたように本記事のコードでの用法は一貫していません。
CARDS.first(1) +
SUITS.first(2).flat_map { [Card[_1, 'A'], Card[_1, 'K']] }
![🔗]()
step
本記事のコードでは、ストレートがフラッシュと誤認されないよう残りのカードをスキップするために、Rubyのstepを用いています。
(0..RANKS.size).step(2).first(5).map { Card['S', RANKS[_1]] }
ここではインデックスを用いています。
![🔗]() まとめ
まとめ
本記事を書くためにだいぶさまよいました。特にコードを適切に実行する部分で苦労しました。皆さんが本記事を楽んでくださり、パターンマッチングについて少しでも得るところがあれば幸いです。
Ruby 3にはまだまだお楽しみがいっぱい隠れています。たまにはRubyで心置きなく遊びましょう!
関連記事
Ruby 3.0でアドベント問題集を解く(1日目)修正のレポート(翻訳)
Rubyでわかる「時計もモノイドの一種」(翻訳)


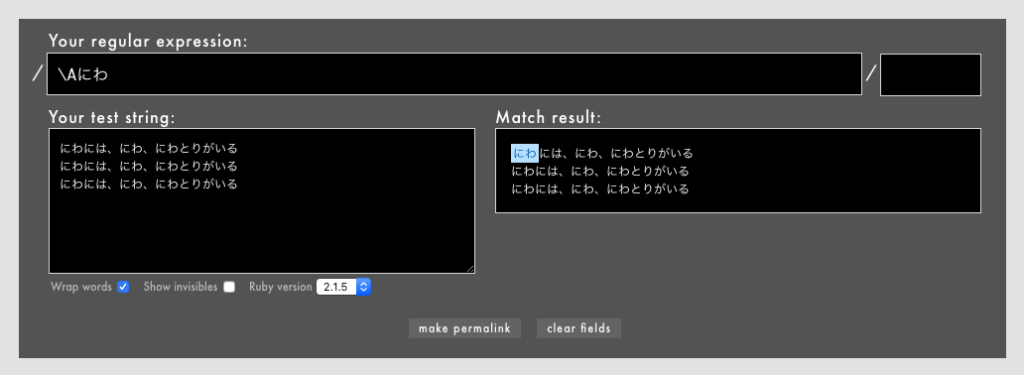
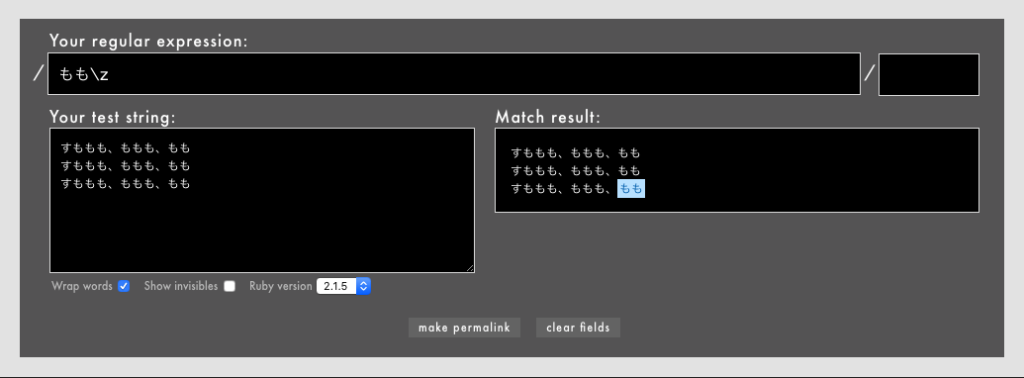
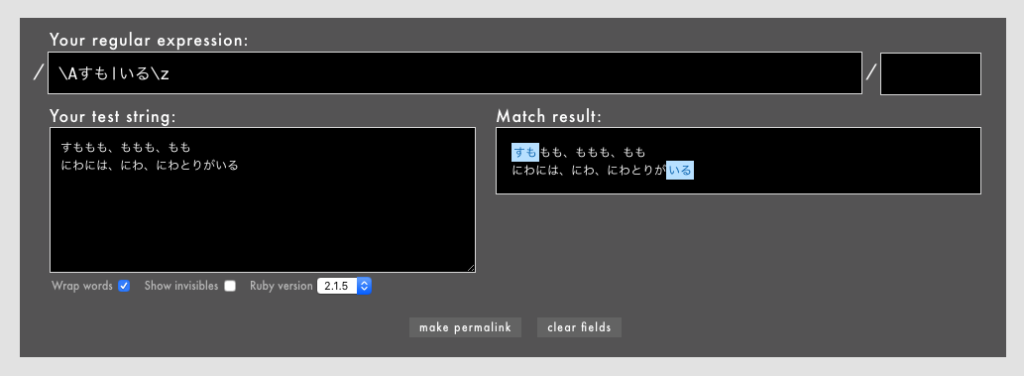
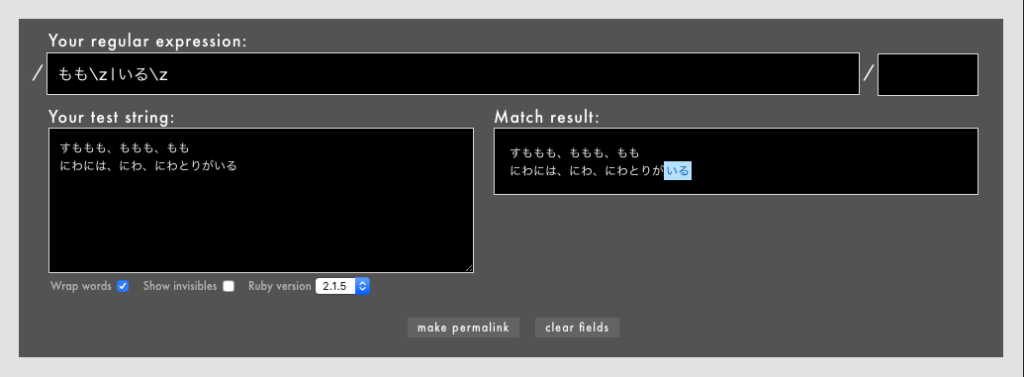
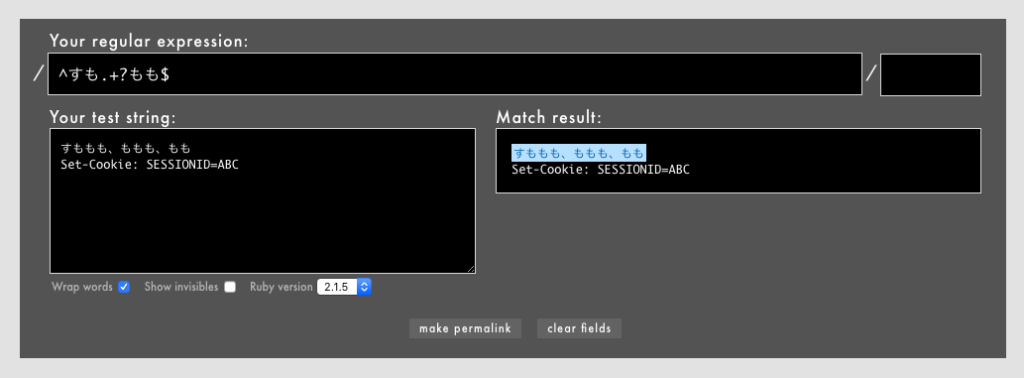
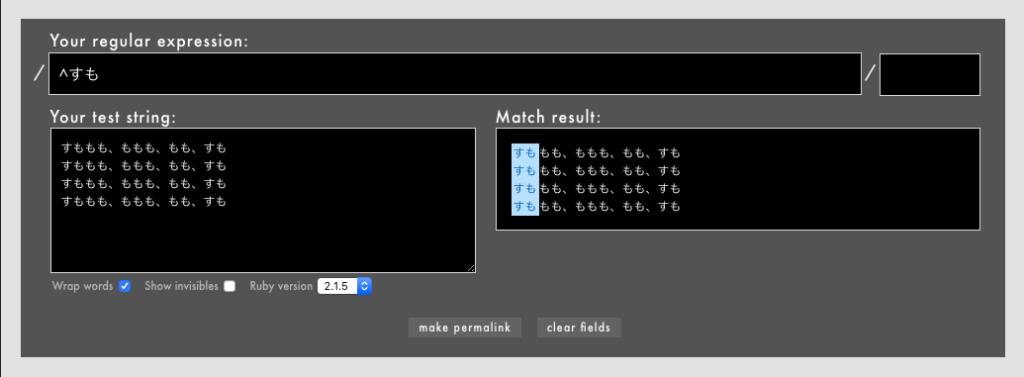
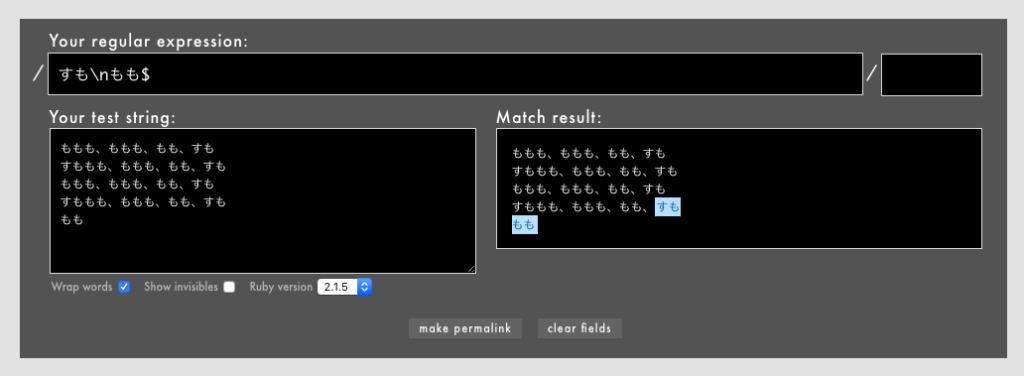
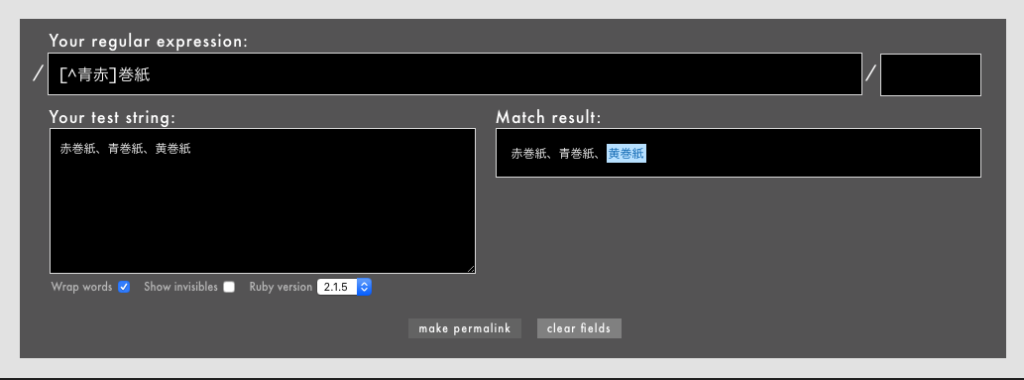
 警告: 冒頭や末尾を
警告: 冒頭や末尾を
 。
。





 でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ


 」
」



 」「気持ちわかります」「お気持ちお気持ち」「なおwaringやマイグレーション時にいろいろエラーが出ました」
」「気持ちわかります」「お気持ちお気持ち」「なおwaringやマイグレーション時にいろいろエラーが出ました」



 」「たしかに」
」「たしかに」


 」
」







 」
」

 」
」



 」
」


 (@ima1zumi)
(@ima1zumi) 







 」
」




 」「こんなメソッドあるの知らなかった〜」
」「こんなメソッドあるの知らなかった〜」















 」「こんなのが隠れてたなんて!」
」「こんなのが隠れてたなんて!」
 」
」
 」
」 」
」

 (@grethlen)
(@grethlen) 

概要
原著者の許諾を得て翻訳・公開いたします。