
こんにちは、hachi8833です。RubyKaigi Takeout 2021のスケジュール/講演タイトル/スピーカーが発表されました。
RubyKaigiの講演内容見てるとテンション高まってくる!https://t.co/easZGBSXob
— igaiga (@igaiga555) August 16, 2021
![🔗]() Rails: 先週の改修(Rails公式ニュースより)
Rails: 先週の改修(Rails公式ニュースより)

今回は以下の公式更新情報からです。既に次の更新情報もいくつか出ています。
- 更新情報: Favicons, InvalidAuthenticityToken message gains, Journey optimizations and more! | Riding Rails
![🔗]()
/favicon.icoへの内部ルーティングを追加
つっつきボイス:「今までrails newするといつも/favicon.icoでエラーになっていたのでエラー抑制用のコンフィグをいつも足していましたけど、ついに修正されたんですね」「お〜マジで、このエラーいつも目にしていました」「よかった 」
」
# railties/lib/rails/templates/rails/welcome/index.html.erb
<% ruby_on_rails_logo_favicon_data_uri = "data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMzIwcHgiIGhlaWdodD0iMzIwcHgiIHZpZXdCb3g9IjAgMCAzMjAgMzIwIiB2ZXJzaW9uPSIxLjEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyIgeG1sbnM6eGxpbms9Imh0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsiPgogICAgPHRpdGxlPkljb248L3RpdGxlPgogICAgPGcgaWQ9Ikljb24iIHN0cm9rZT0ibm9uZSIgc3Ryb2tlLXdpZHRoPSIxIiBmaWxsPSJub25lIiBmaWxsLXJ1bGU9ImV2ZW5vZGQiPgogICAgICAgIDxnIGlkPSJSdWJ5LU9uLVJhaWxzLUxvZ28iIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUuMDAwMDAwLCAyMC4wMDAwMDApIiBmaWxsPSIjRDgxRTAwIj4KICAgICAgICAgICAgPHBhdGggZD0iTTIxLjkzMzA3MDYsMjg1IEwxNjguMTc1NDI2LDI4NSBDMTQ3Ljk0MDg1OCwxNTAuNjkxNzA2IDE5Ni44ODIzODMsNjYuMzE0MjkwMiAzMTUsMzEuODY3NzUzNiBDMzE1LDIxLjc4NTEyODQgMzE1LDMxLjg2Nzc1MzYgMzE1LDIxLjc4NTEyODQgQzE2MS4yNTI4MywyNC45MTE2Mjc4IDYzLjU2Mzg1MzMsMTEyLjY0OTkxOCAyMS45MzMwNzA2LDI4NSBaIiBpZD0iUGF0aCIvPgogICAgICAgICAgICA8cG9seWdvbiBpZD0iUGF0aCIgcG9pbnRzPSI0MC40MDgyNjQzIDE4NS45MTU3MSAxMi43MzI2NDk0IDE3NC40MDE2NjMgLTEuNDIxMDg1NDdlLTE0IDIwNS40NDI3MSAyOS41NzExOTY2IDIxNi42NDcxMTUiLz4KICAgICAgICAgICAgPHBvbHlnb24gaWQ9IlBhdGgiIHBvaW50cz0iMTgwLjQ3MzEwMiAyNjguMDczNjQzIDIwNC45MzYwMTYgMjc2LjQxMDk2NiAyMDQuOTM2MDE2IDI1NC41MDg2NzMgMTgwLjQ4OTY0NCAyNDQuMzM4MTA3Ii8+CiAgICAgICAgICAgIDxwb2x5Z29uIGlkPSJQYXRoIiBwb2ludHM9IjEwMC41ODk1MTkgOTcuMjI4NzYwNiA3Ni42ODQwMTU2IDc5LjE2ODcwMjEgNTUuMjQ0MDc5MSAxMDAuMTgzMTA1IDgxLjUxNDMyMzkgMTE3LjQzMzcyNSIvPgogICAgICAgICAgICA8cG9seWdvbiBpZD0iUGF0aCIgcG9pbnRzPSIxODQuNTc1Njc5IDE4NC44OTYyOTUgMjA3Ljk1MjAzIDIwMC4yNDY2MSAyMTEuNzI3NzI5IDE4MS4yMDUyNjYgMTg5Ljg2MzY1MyAxNjQuNjg3NDYiLz4KICAgICAgICAgICAgPHBvbHlnb24gaWQ9IlBhdGgiIHBvaW50cz0iMjYxLjczNDAxIDY1Ljg5NTk0NDYgMjY5LjM1NDIzNCA4Mi4zMjk1NCAyODUuMzE4MjU2IDcyLjcwNDg1OTYgMjc4LjMxMDEyOSA1Ni45ODI5ODk1Ii8+CiAgICAgICAgICAgIDxwb2x5Z29uIGlkPSJQYXRoIiBwb2ludHM9IjI2MS45MTM3IDE2LjE4NDU0NzMgMjU1LjU5ODQ3OSA3LjEwNTQyNzM2ZS0xNSAyMzIuNzk2MDIgMy40ODg5NjMyMyAyNDAuNDYzODczIDIwLjAyNTI3MjUiLz4KICAgICAgICAgICAgPHBvbHlnb24gaWQ9IlBhdGgiIHBvaW50cz0iMjExLjkzNDExOSAxMTEuNTgwNjc1IDIyNi43MjI1NDcgMTI3Ljc5MjYwMSAyMzguMDIzOTI1IDExMy45MDM3MTUgMjIzLjQ2ODM3NSA5Ni41NDY4Njg1Ii8+CiAgICAgICAgICAgIDxwb2x5Z29uIGlkPSJQYXRoIiBwb2ludHM9IjE3OS42ODY4NTggMzguNDk1MjIxOCAxNjQuNjQxOTMxIDIwLjAyNTI3MjUgMTM5Ljg0NzYyIDMyLjU1NTI5OTIgMTU2LjYwMTMyNCA1MC45MjE2NzUzIi8+CiAgICAgICAgPC9nPgogICAgPC9nPgo8L3N2Zz4=" %>
<!DOCTYPE html>
<html>
<head>
<title>Ruby on Rails</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width">
<link rel="shortcut icon" href="<%= ruby_on_rails_logo_favicon_data_uri %>" />
「よく見るとRailsのファビコンをsvgで追加しているんですね」「これっていいんだろうか?」「このファビコンをデフォルトのまま使い続けると、そのWebアプリがRails製ということがそこから推測できるので、個人的にはRailsのファビコンよりはゼロバイトの画像を返すなどの方が、推測の手がかりを増やさないという点で好ましいかもしれないと思いました」「それもそうですね」「アプリがどんな言語やフレームワークでできているかというシグネチャ情報の収集は、攻撃の予備動作にもなりえます」
![🔗]()
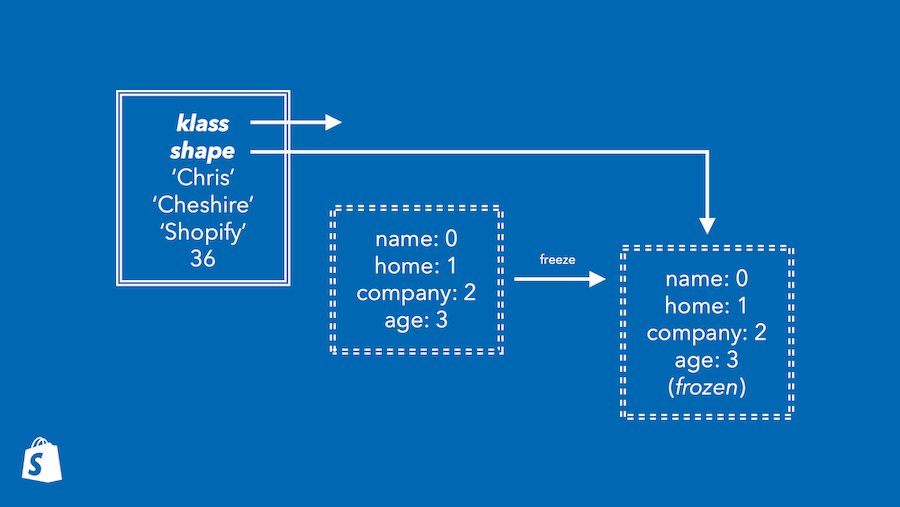
Journey::Astを追加
つっつきボイス:「ASTは抽象構文木ですね」「JourneyはRailsのAction Dispatchのルーティング周りに関連するモジュールだったかな」「Journeyって今言われるまで全然知りませんでした」「Railsのルーティングになぞらえて旅(journey)という言葉をかけたのかも」
参考: 抽象構文木 - Wikipedia
参考: rails/actionpack/lib/action_dispatch/journey at main · rails/rails
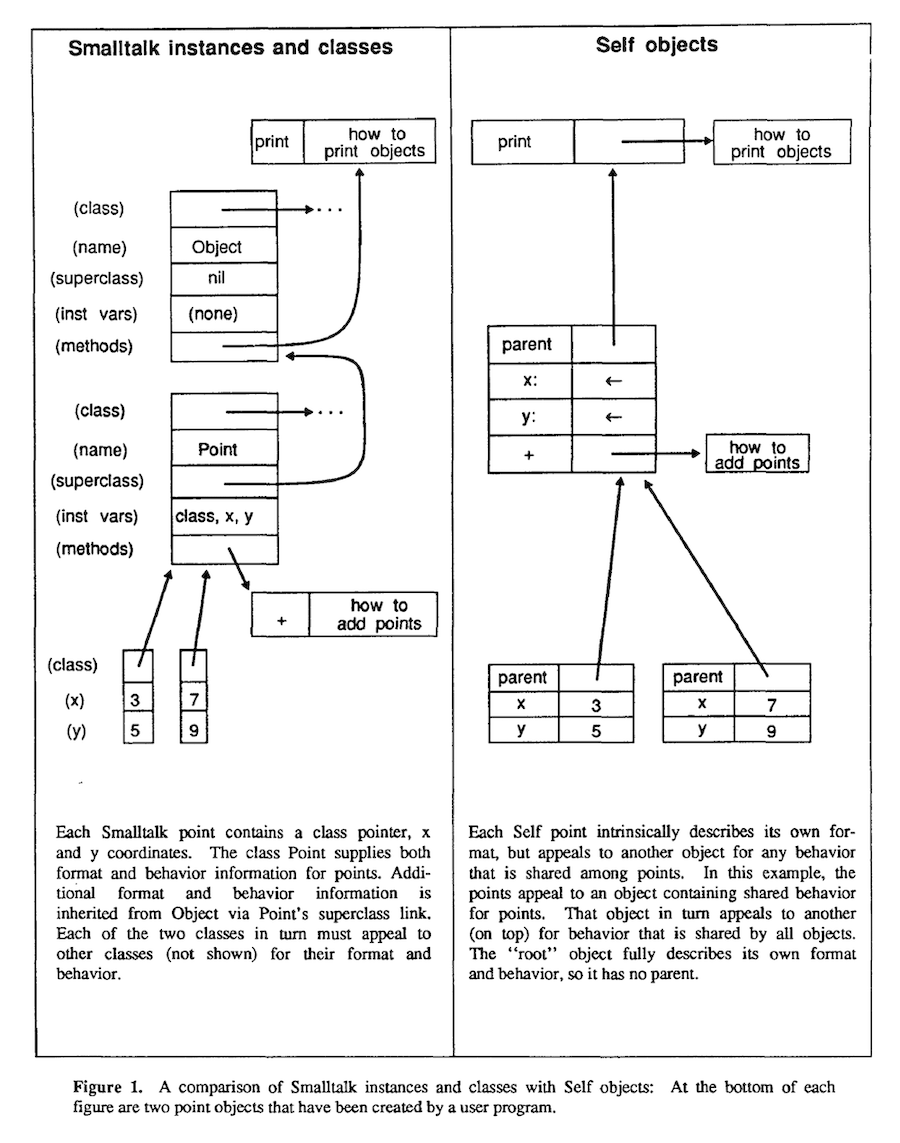
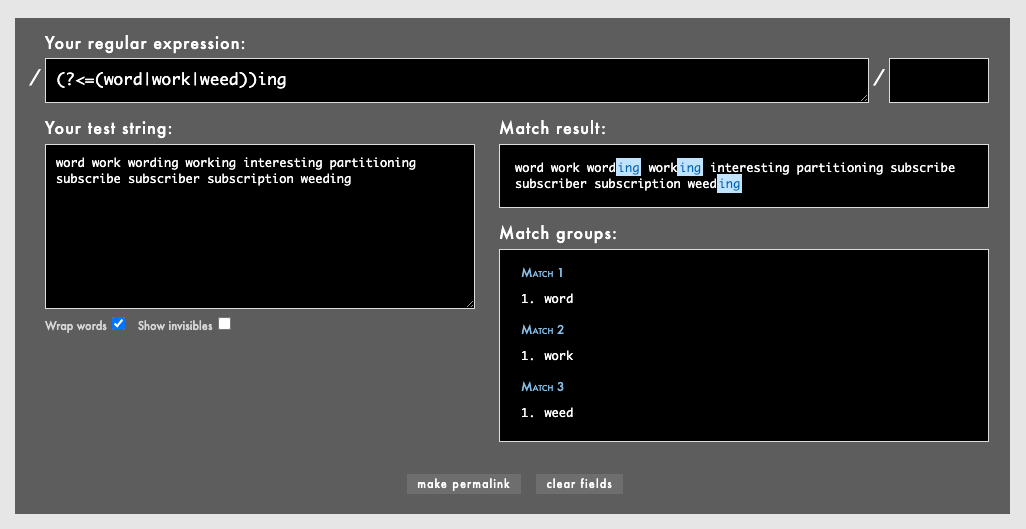
「今見つけた記事↓にあるこの図がASTをNFA(非決定性有限オートマトン)で表したものですね」「こういうふうになるのか〜」
参考: Railsのルーティングを支える技術 - Journeyについて - Qiita
『Railsのルーティングを支える技術』より

「このJourney::Astはルーティング周りのパフォーマンス改善のために追加されたみたい」「不要なルーティング探索をJourney::Astで削減したんですね」「RailsのJourneyを触れる人はなかなかいないという話を聞いたことがありますけど、久しぶりにJourneyが改修された 」
」
# 同PRより
master:
TOTAL (pct) SAMPLES (pct) FRAME
52 (0.5%) 52 (0.5%) ActionDispatch::Journey::Nodes::Node#symbol?
58 (0.5%) 45 (0.4%) ActionDispatch::Journey::Scanner#scan
45 (0.4%) 45 (0.4%) ActionDispatch::Journey::Nodes::Cat#type
43 (0.4%) 43 (0.4%) ActionDispatch::Journey::Visitors::FunctionalVisitor#terminal
303 (2.7%) 43 (0.4%) ActionDispatch::Journey::Visitors::Each#visit
69 (0.6%) 40 (0.4%) ActionDispatch::Routing::Mapper::Scope#each
this commit:
TOTAL (pct) SAMPLES (pct) FRAME
82 (0.6%) 42 (0.3%) ActionDispatch::Journey::Scanner#next_token
31 (0.2%) 31 (0.2%) ActionDispatch::Journey::Nodes::Node#symbol?
30 (0.2%) 30 (0.2%) ActionDispatch::Journey::Nodes::Node#initialize
![🔗]() メッセージ改善2件
メッセージ改善2件
つっつきボイス:「1件目はActionController::InvalidAuthenticityTokenをraiseするときにwarningも表示するようになった」「Ruby on Rails Discussionsで提案した人がプルリク投げてるんですね↓」
「Railsを始めて間もない人にとっては何が起こっているかわかりにくいと思うので、warningも欲しいのはワカル」「今でもエラーを見てググれば調べられますけどね」「Webのセキュリティ関連要素も昔より増えてきましたし、ググって見つけた情報が古い可能性もあるので、warningも出力する方が親切でしょうね」
# actionpack/lib/action_controller/metal/request_forgery_protection.rb#L225
class Exception
+ attr_accessor :warning_message
+
def initialize(controller)
@controller = controller
end
def handle_unverified_request
- raise ActionController::InvalidAuthenticityToken
+ raise ActionController::InvalidAuthenticityToken, warning_message
end
# actionpack/test/controller/request_forgery_protection_test.rb#L710
+ def test_raised_exception_message_explains_why_it_occurred
+ forgery_protection_origin_check do
+ session[:_csrf_token] = @token
+ @controller.stub :form_authenticity_token, @token do
+ exception = assert_raises(ActionController::InvalidAuthenticityToken) do
+ @request.set_header "HTTP_ORIGIN", "http://bad.host"
+ post :index, params: { custom_authenticity_token: @token }
+ end
+ assert_match(
+ "HTTP Origin header (http://bad.host) didn't match request.base_url (http://test.host)",
+ exception.message
+ )
+ end
+ end
+ end
「2件目は、今までだとbin/rails db:migrate -hでrakeの一般的なヘルプが表示されていたのを、db:migrateのヘルプを出せるようになったみたい」「ヘルプの量が増えるとrakeのヘルプが邪魔になりがちでしたね」「これでググらずに調べられる」
![🔗]()
config_accessorアクセサでデフォルト値を定義できるようになった
つっつきボイス:「ActiveSupport::Configurableのアクセサにdefault:オプションを渡せるようになったのか」「イニシャライザで設定しなくてもよくなった 」「これはある方がよいでしょうね:
」「これはある方がよいでしょうね: ActiveSupport::Configurableはあまり使ったことはありませんが、Active Supportにはこういう地味に便利な機能がまだまだあります」
# activesupport/test/configurable_test.rb#L65
test "configuration accessors can take a default value as an option" do
parent = Class.new do
include ActiveSupport::Configurable
config_accessor :foo, default: :bar
end
assert_equal :bar, parent.foo
end
参考: ActiveSupport::Configurable の話 - scramble cadenza
![🔗]()
Middleware#removeがMiddleware#delete!にリネーム
- PR: “Middleware#remove” is renamed “Middleware#delete!” by sato11 · Pull Request #42867 · rails/rails
つっつきボイス:「前回マージされたMiddleware#remove(ウォッチ20210810)がさらにリネームされてMiddleware#delete!になったそうです」「また変わった 」「早!」
」「早!」
「元々Middleware#deleteという前からあった機能がエラーをraiseするように変更されていたんですが、挙動を変えると互換性に問題があることがわかったので前回Middleware#deleteを元に戻してMiddleware#removeを追加したいう流れでした: でもdeleteとremoveが両方存在して機能が違うのはたしかにわかりにくそうなので、今回Middleware#removeをMiddleware#delete!にリネームしたということみたい」
「たしかに!でエラーをraiseする方がRubyっぽくてわかりやすいかも」「!を付けたらエラーをraiseするというのはActive Recordのfind_byとfind_by!やcreateとcreate!、saveとsave!などの使われ方に沿った挙動でしょうね: 一方”!があるとより破壊的になる”と考えれば、!を付けると無言で削除する方がより破壊的とも言えるので、どちらの命名がよいかは悩ましいかも」「あ、そうか」「この#42867の場合は既存のdeleteを変えたくないという事情があったので、!を付けたらエラーをraiseする方に倒すしかなさそうかな」「たしかに」
![🔗]() Rails
Rails
![🔗]() カウンタキャッシュをスレッドセーフに更新する(Ruby Weeklyより)
カウンタキャッシュをスレッドセーフに更新する(Ruby Weeklyより)
つっつきボイス:「カウンタキャッシュ更新の競合状態を防ぐ記事ですね: これは昔からよく問題になっています」「そうそう」
「以下のサンプルコードのようにマルチスレッドを絡めてみると割とすぐ競合が発生する」
# 同記事より
class UnsafeTransaction
def self.run
account = Account.find(1)
account.update!(balance: 0)
threads = []
4.times do
threads << Thread.new do
balance = account.reload.balance
account.update!(balance: balance + 100)
balance = account.reload.balance
account.update!(balance: balance - 100)
end
end
threads.map(&:join)
account.reload.balance
end
end
参考: class Thread::Mutex (Ruby 3.0.0 リファレンスマニュアル)
「記事ではミューテックスやActive Recordのlock!で回避する方法のほかに、Active Recordのupdate_countersメソッドのアトミックな性質を使って競合を回避する方法も紹介されている↓」「へ〜!」「面白いけど、Rubyのようなスクリプト言語でアトミックとか意識したくない気持ちもちょっとあるかな: C言語などでは普通の発想なんですが」
# 同記事より
class CounterTransaction
def self.run
account = Account.find(1)
account.update!(balance: 0)
threads = []
4.times do
threads << Thread.new do
Account.update_counters(account.id, balance: 100)
Account.update_counters(account.id, balance: -100)
end
end
threads.map(&:join)
account.reload.balance
end
end
参考: ミューテックス - Wikipedia
参考: lock — ActiveRecord::Locking::Pessimistic
「お、concurrent-rubyにはAtomicFixnumというクラスがあるのか↓: 実際の内部実装ではミューテックスあたりを使っていそうに見える」

「トランザクションを張ったうえで別途カウンタキャッシュを更新するコードを書くと、たまに競合が発生するという問題は実は昔からあって、真面目に回避しようとすると複雑になりがち」「ふむふむ」「カウンタキャッシュはRailsの機能などを使えば簡単に実現できるんですが、複雑なトランザクションが絡んでくるとデッドロックしたりする: そこに引っかかるようなコードを書かなければたいてい問題にならないので、経験している人もいれば経験せずに済む人もいたりします」
「発生の可能性がつきまとうのはカウンタキャッシュの仕組み上仕方ないんですが、カウンタキャッシュで競合が起きる可能性があるということだけでも知っておくと損はないと思います: よさそうな記事」
「ところで、記事の末尾にあるリンクをたどるとハイゼンバグ(Heisenbug)という知らない用語があったんですが、やはり『ハイゼンベルグの不確定性原理』のもじりでした」「調査しようとすると競合状態が変わって再現が難しいマルチスレッド系バグとかが、ちょうどそういう感じでしょうね」
参考: 特異なバグ - Wikipedia
参考: 不確定性原理 - Wikipedia
![🔗]() Railsアプリでコードをdeprecateする(Ruby Weeklyより)
Railsアプリでコードをdeprecateする(Ruby Weeklyより)
つっつきボイス:「アプリでのdeprecationの書き方の記事」「ウォッチの『先週の改修』ではよく見かけますけど、考えてみたらアプリのコードでもRailsのActiveSupport::Deprecationを使っていいんですね」「もちろん使っていいんですよ」「オープンソースのRailsアプリなどで普通に有効な書き方ですね」
def process_widget
ActiveSupport::Deprecation.warn(
"#process_widget is deprecated. " \
"Use #send_widget_to_processor instead."
)
# other code ...
end
- Rails API: ActiveSupport::Deprecation
「ActiveSupport::Deprecationで書いておくと、テストコードを回したときにもdeprecation warningが表示されるのが便利です」「なるほど!」
![🔗]() NokogiriがHTML5の機能をサポート(Ruby Weeklyより)
NokogiriがHTML5の機能をサポート(Ruby Weeklyより)
つっつきボイス:「CRuby限定でNokogiriがHTML5をサポートしたそうです」「Nokogiriにマージされたnokogumboって何だろう↓」「初めて見ました」

「お〜、nokogumboはHTML5のfragmentや内部フェッチやカスタム属性とかも使えるのか↓: これまでNokogiriがHTML5を読み込めなかったのかと思ったら、HTML5のこうした機能がNokogiriで使えるようになったということのようですね」「なるほど」
# rubys/nokogumboより: fragmentのパース
require 'nokogumbo'
doc = Nokogiri::HTML5.fragment(string)
# rubys/nokogumboより
require 'nokogumbo'
doc = Nokogiri::HTML5.get(uri)
参考: Links - The complete HTML5 tutorial
参考: data-* - HTML: HyperText Markup Language | MDN
「今回はNokogiriのマイナーバージョンアップで大きな改修ではなさそうなので、従来どおりにも使えそうかな」「nokogumboがCで書かれているのでJRubyとかでは動かないのはしょうがない」
![🔗]() GitLabのArmベースAWS Graviton2記事
GitLabのArmベースAWS Graviton2記事
そのためのARMだから当たり前だけど、AWSでARMコアの方が安くて早いhttps://t.co/ljQAknvbl8 #development #software #devops #gitlab #live
— Takuya Ono 小野卓也 (@takuya_ono) August 6, 2021
つっつきボイス:「へ〜、GitLabをArmベースのAWS Graviton2インスタンスに置くと23%安くなって36%パフォーマンスが向上するという記事」「この図はGitLabがベンチマークに使った環境なのね↓」
同記事より

「AWS Gravitonがわかってなかった 」「AWSが作っているArmプロセッサのインスタンスですね: 出たのは最近ですが、もう割と使われていると思いますよ」「なるほど、それの新しいのがGraviton2ですか」
」「AWSが作っているArmプロセッサのインスタンスですね: 出たのは最近ですが、もう割と使われていると思いますよ」「なるほど、それの新しいのがGraviton2ですか」
参考: AWS Graviton (EC2 に最良の料金とパフォーマンスを提供 | AWS
参考: AWS Graviton2 を搭載した新しい EC2 M6g インスタンス | Amazon Web Services ブログ
「RDBMSなら今でもArmプロセッサでまったく問題なく動かせますが、GitLabのような大規模Railsアプリで使われているgemをArmプロセッサ上でビルドして実行できたということは、BPSが今メインで使っているGitLabサーバーも、原理的にはArmベースのAWS Graviton2インスタンスに引っ越し可能ということになりますね」「お〜」「社内でも検討してみようかな」
前編は以上です。
バックナンバー(2021年度第3四半期)
週刊Railsウォッチ: システムテスト用headlessドライバにCupriteが追加、rails-mini-profiler、Jeremy Evansインタビューほか(20210810)
- 20210804後編 Rubyの可変長アロケーションプロジェクト、サーキットブレーカーgem、EC2-Classicが終了へほか
- 20210803前編 SorbetでRailsアプリの型シグネチャを書く、activerecord-cte gemとanycable-client gem
- 20210720後編 ruby-gitでGit操作、最近のruby/debug、stdgems.org、Windows 365 Cloud PCほか
- 20210719前編 GitHubによるdisable_joins解説、MemoWise gemでメモ化、RailsのDDoS攻撃対策ほか
- 20210713後編 ruby-spacyで自然言語処理、Ruby製x86-64アセンブラ、『タイムゾーン呪いの書』ほか
- 20210712前編 AR::Relation#destroy_allがバッチ分割に変更、Active Record暗号化解説、sidekiq-unique-jobsほか
- 20210706後編 GitHub CopilotのAI補完、Pure Ruby実装のRuby JIT rhizome、PostgreSQLのPG-Strom拡張ほか
- 20210705前編 DI的な書き方が必要なとき、脆弱性学習用アプリRailsGoat、brakemanは優秀ほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやはてブやRSSやruby-jp SlackやRedditなど)です。
Rails公式ニュース
Ruby Weekly

The post 週刊Railsウォッチ: カウンタキャッシュをスレッドセーフに更新、Journey::Ast追加、GitLabをAWS Graviton2で動かすほか(20210818前編) first appeared on TechRacho.

 。
。




 :
: 
















 。
。



 (@p_ck_)
(@p_ck_) 






 内容は「メソッドを操る」です、詳細は当日のお楽しみ
内容は「メソッドを操る」です、詳細は当日のお楽しみ



 Rails
Rails (@Yuppyhappytoyou)
(@Yuppyhappytoyou) 

 )
)

















 →
→  →
→  (@coe401_)
(@coe401_) 
 (@udzura)
(@udzura) 





 濃厚すぎてとてもまとめられない…
濃厚すぎてとてもまとめられない…

 (@ima1zumi)
(@ima1zumi) 























 | Riding Rails
| Riding Rails








 」
」




 」「
」「



週刊Railsウォッチについて
TechRachoではRubyやRailsなどの最新情報記事を平日に公開しています。TechRacho記事をいち早くお読みになりたい方はTwitterにて@techrachoのフォローをお願いします。また、タグやカテゴリごとにRSSフィードを購読することもできます(例:週刊Railsウォッチタグ)